
Correct by construction
No timing required
Synthesize your design directly from your functional specification. Synthesis is correct by construction and generates circuits that function correctly regardless of timing. This dramatically reduces the need for both functional and timing verification allowing you to focus on your product.
Click and scroll to synthesize the circuit


Automating physical design
Cell layouts are generated automatically. Design rules are specified through a simple python interface. Only 14 minutes to layout all 2752 cells in the Skywater PDK. What would have taken 40 people 5 months to do manually has been reduced to a coffee break.
See the spec for Skywater 130nm.
 Click to see the commands that generated these cells
Click to see the commands that generated these cells
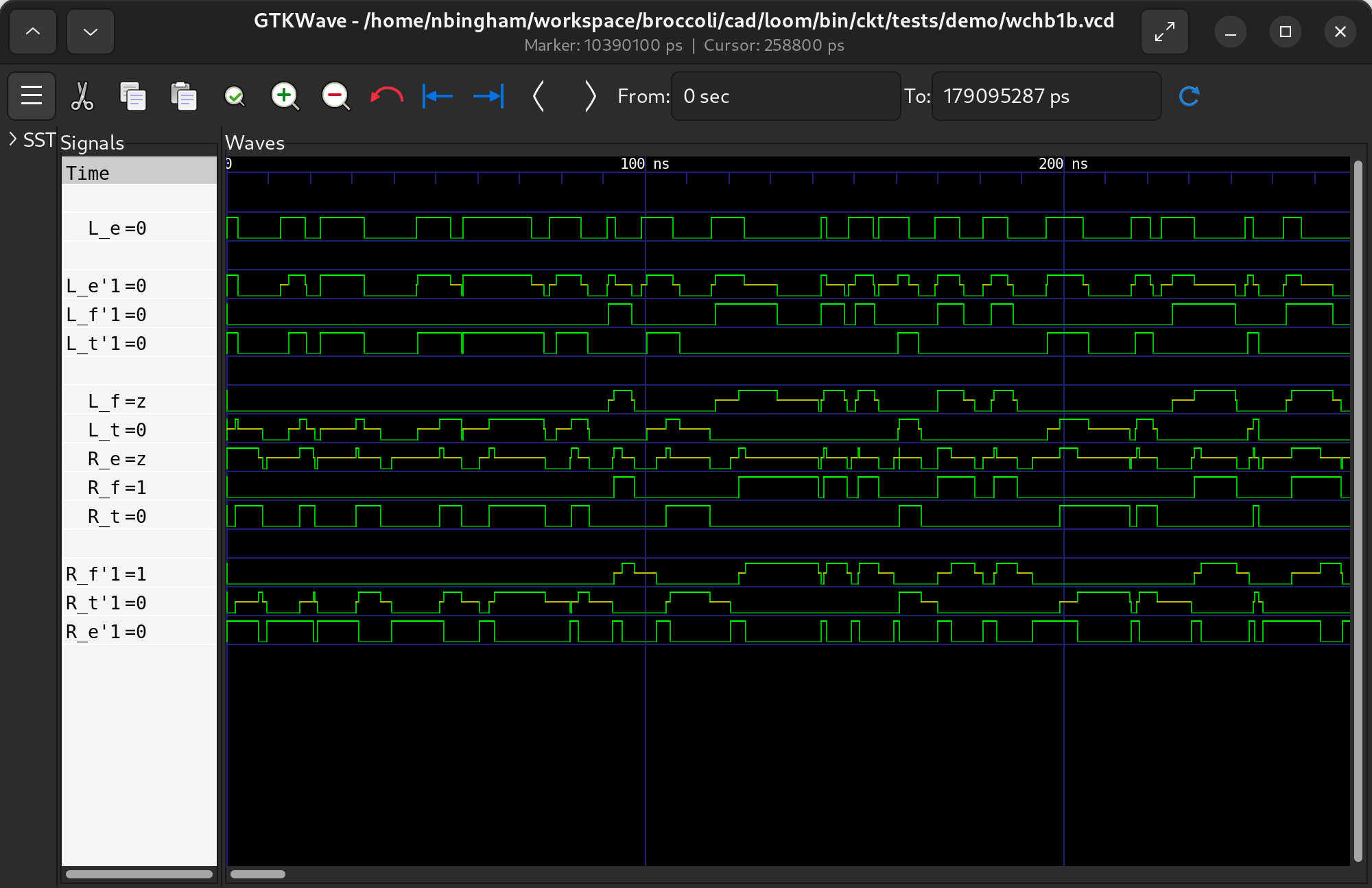
Flexible to your needs
Want to make low level changes in the compiled circuits? Simulate your behavioral and digital specifications with random timing for verification. View the results in gtkwave or work directly on the command line.
Click and scroll to see the interactive CLI
Broccoli was founded in December of 2021 to bring about a categorical improvement in compute performance, and we believe that asynchronous design is the next step. With asynchronous design, it is possible to implement complex control that takes advantage of pareto rules in the workload to dramatically improve performance and power. However, asynchronous design has proven to be far too difficult for commercial viability. Our first step toward achieving our mission is to remove that blocker with Loom.